(This post is dated, and was originally posted on LinkedIn and Twitter Week 1, 2024)
Most news is not new, but repetition.
We consume a lot of news ‘stories’ through a variety of channel, but a lot of these stories are flavored repetition of limited information available elsewhere. The editing process is mostly opaque, even though it decides what stories we see and think about.
Consider a war event. Say reporter A is at site and interviews and gets a comprehensive understanding of the event. Person B, is in the same city, but didn’t actually go and talks to A. Person C is in a different city/country and talks to B. Person D listens to a briefing from person C’s organization. And so on.
Now, all of them pose as credible sources, when only A was actually there. (This is over-simplified since networks, fixers, handlers are key for comprehensive stories.) But we get different flavors of only slightly different information, and a large number of stories in our channels. Vanessa Otero‘s media bias chart tries to dissect such editing decisions via fact vs analysis vs opinion at a publication track record level.
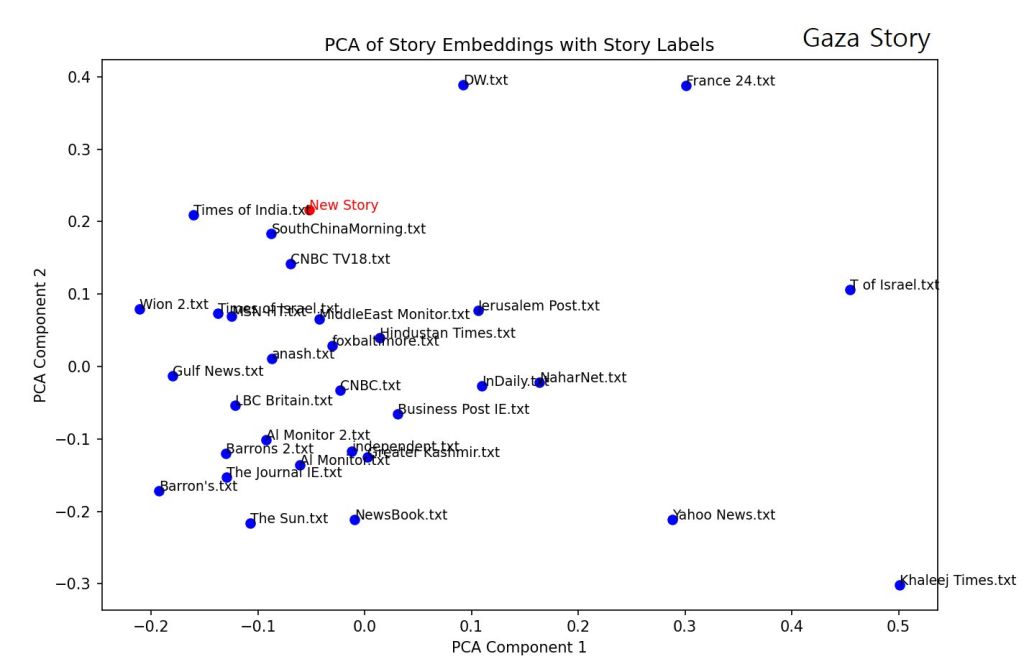
Over new year’s, I tried to answer “If we look at news stories about an event, on a given day, can find which ones came from the same source?” Why? Because if 10 people come from an event with the exact same information, 9 of them are unnecessary but still end up influencing my decision making – Our minds act as censors but can be skewed with overload and poor sampling.
So, I looked at news stories from a given day, about 2 events:
1. Death of Hamas deputy leader in the ongoing war in Gaza.
2. Wedding called off due to Bone Marrow not being served, in India.
The following graphs show clusters based on sources. My expectation was clusters close together – clusters indicating stories emerging from the same source, and smaller distance between clusters indicating the sources being similarly “potent/original”. I used OpenAI’s da vinci (GPT-3) for story analysis and simple ML for clustering and PCA.
Visualizing different sources, can show us what parts of reporting about an event/story/conversation (national, regional or local) are missing – i.e. for what missing parts of the story should we be looking for sources. News ‘stories’ are often packaged as complete in themselves, closing the mental loop for analysis. A site/browser extension that tracks and filters stories or shows this ‘meta organization’ might be a start, although there might be better ways to achieve this. I also really like John Gable and Joan Blades‘s philosophy with AllSides in finding a fuller picture (atleast for US based reporting).
The code is imperfect and incomplete, and I’ve exceeded my OpenAI credits, but I’m interested in seeing if there’re others interested in the question, or are already working in the space. Seems like a market failure that might benefit from an Open Source watchdog.


Leave a comment